
The SaaS AI Imperative: Scale Securely or Get Left Behind
Modern SaaS platforms are racing to embed AI capabilities, but traditional LLM deployment approaches crumble under multi-tenant requirements:✔ Enterprise software demands strict data segregation across client workspaces
✔ A healthcare SaaS needs HIPAA-compliant isolation between medical practices
✔ An e-commerce platformAn e-commerce platform requires brand-specific AI personalities
The breakthrough? Virtualization through PagedAttention and adaptive fine-tuning Virtualization through PagedAttention and adaptive fine-tuning - the same paradigm that revolutionized cloud computing, now applied to LLMs.Key Benefits
✔ Security – Tenant data never mixes.✔ Efficiency – No need to load separate models per user.
✔ Scalability – Serve 100s of users on one GPU.
Under the Hood: PagedAttention - The Game Changer
Why Memory Management Makes or Breaks Multi-Tenant AI
Traditional LLM serving wastes 60-70% of GPU memory on:- Over-provisioning (allocating worst-case memory per request)
- Fragmentation (unusable gaps between variable-length sequences)
PagedAttention solves this by:
- Treating GPU memory like an OS treats RAM - using paging
- Breaking sequences into fixed-size blocks (typically 16 tokens)
- Dynamically allocating blocks across tenants as needed
The Technical Magic
- Block Tables
- hared Memory Pool
- Zero Waste
Architectural Blueprint for SaaS
Layer 1: The Isolation Foundation
PagedAttention(via vLLM) provides:- Hard security boundaries through separate KV caches
- Performance isolation via quality-of-service controls
- Predictable scaling with linear memory growth per active tenant
Layer 2: The Personalization Engine
LoRA Adapters enable:- Vertical specialization: Medical vs legal language models
- Horizontal customization: Brand voice adjustments
- Continuous learning: Per-tenant incremental updates
Layer 3: The Control Plane
- Tenant-aware routing (JWT claims → adapter selection)
- Dynamic provisioning (cold adapters load on-demand)
- Usage telemetry (cost attribution per tenant)
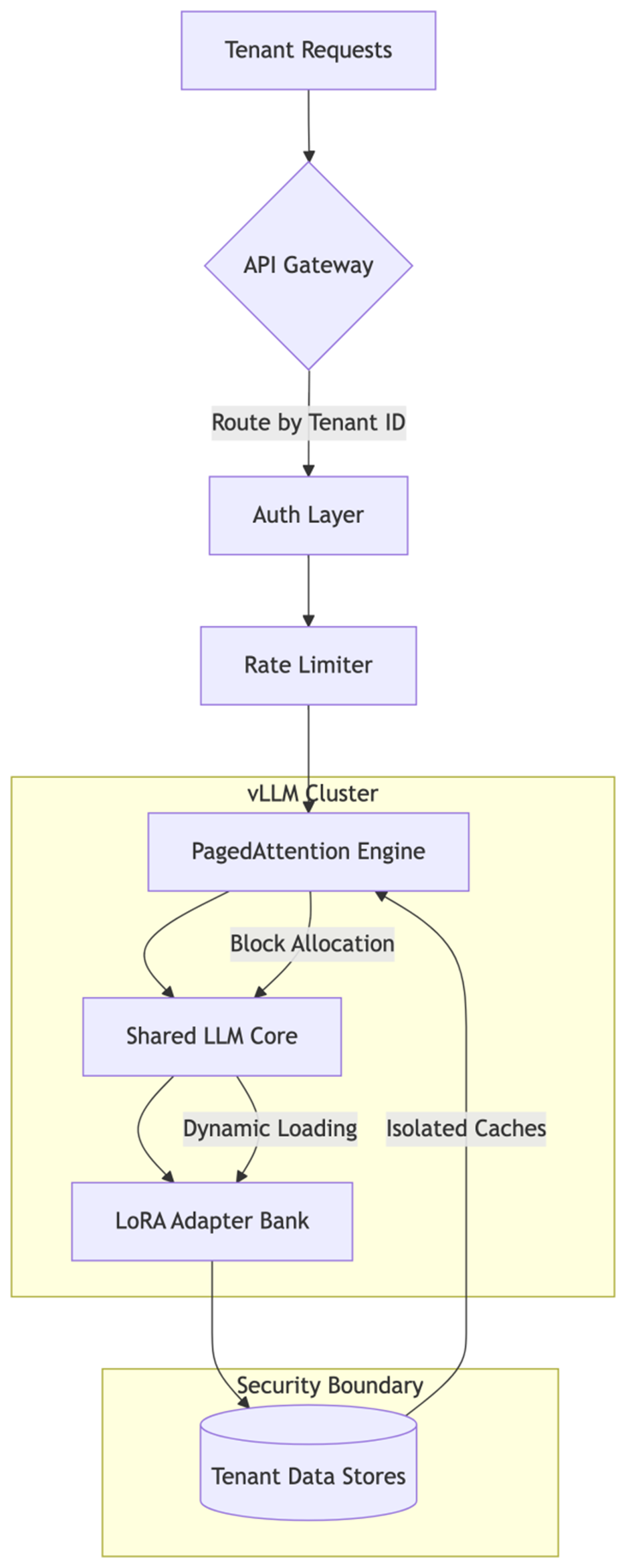
Key Components
- API Gateway
- Auth Layer
- PagedAttention Engine
- Shared LLM Core
- LoRA Adapter Bank
- Tenant Data Stores
Real-World Impact Metrics
SaaS Vertical Problem Solved PagedAttention Benefit Healthcare Cross-patient data leakage 100% cache isolation Financial Compliance audits Exact memory attribution EdTechDistrict-specific content Zero-config scaling
Performance Gains:
- 3-5x more tenants per GPU vs. baseline
- 90th percentile latency reduced by 40%
- Memory overhead cut from 4GB→0.5GB per tenant
The Future: Beyond Basic Virtualization
- Tiered Isolation
- Semantic Routing
- Cold Start Optimization
Let's Discuss
- SaaS Architects: How are you solving the multi-tenant AI challenge?
- ML Engineers: What PagedAttention tricks have you discovered?
- Founders: What AI features are your customers demanding?
